Database Normalization
Last Updated 2/15/2024
INTRODUCTION TO DATABASE NORMALIZATION
In the realm of database design and management, normalization is a critical process that aims to organize data efficiently, reduce redundancy, and ensure data integrity. This introduction provides an overview of database normalization, its objectives, and its significance in creating well-structured and scalable databases.
At its core, normalization seeks to achieve several key objectives:
Objectives of Database Normalization
- Minimize Redundancy: By breaking down data into smaller, more manageable units and organizing it across multiple tables, normalization helps minimize redundant data storage.
- Eliminate Update Anomalies: Normalization ensures that updates or modifications to the database are performed in a single location, reducing the risk of inconsistencies that may arise when the same information is stored in multiple places.
- Enhance Data Integrity: By structuring data according to well-defined rules and dependencies, normalization helps maintain data integrity, ensuring that the database remains accurate and reliable over time.
- Facilitate Scalability and Flexibility: A normalized database schema is inherently more flexible and scalable, making it easier to accommodate changes in requirements and adapt to evolving business needs.
UNDERSTANDING DATABASE TABLES
Database tables are fundamental components of relational database management systems (RDBMS) that store structured data in rows and columns. This section provides an introductory overview of database tables, their structure, and their role in organizing and managing data.
Role of Database Tables
Database tables play a crucial role in organizing and managing data within a relational database. They provide a structured format for storing information in a manner that facilitates efficient data retrieval, manipulation, and analysis. Tables allow data to be logically organized into discrete units, making it easier to understand, maintain, and query the underlying data model.
NORMALIZATION LEVELS
Normalization levels, also known as normal forms, are a series of progressive guidelines used to eliminate redundancy and dependency in database tables. They ensure that each table represents a single subject and that data is stored without unnecessary duplication, thereby minimizing the risk of data anomalies and ensuring data integrity. The normalization process involves decomposing large tables into smaller, more manageable ones, organized in a hierarchical fashion. Here are the common normalization levels:
- First Normal Form (1NF)
- Second Normal Form (2NF)
- Third Normal Form (3NF)
- Boyce-Codd Normal Form (BCNF)
- Fourth Normal Form (4NF)
- Fifth Normal Form (5NF)
Each normalization level represents a higher degree of normalization, leading to a more efficient and robust database design. However, achieving higher normal forms may involve trade-offs in terms of query complexity and performance, so the level of normalization applied should be balanced with the specific requirements and constraints of the database application.
NORMALIZATION TECHNIQUES
Normalization techniques are fundamental procedures in database design aimed at organizing and structuring data to ensure efficiency, minimize redundancy, and maintain data integrity. One of the initial steps in normalization involves functional dependency analysis, where relationships between attributes are identified to determine how they depend on each other. This analysis forms the basis for subsequent normalization steps.
The first normal form (1NF) ensures that each table has a primary key and that all attributes contain atomic values, meaning they cannot be further divided. Repeating groups are eliminated by breaking them into separate rows, ensuring each row represents a single entity or record. Building upon 1NF, the second normal form (2NF) addresses partial dependencies by ensuring that all non-key attributes are fully functionally dependent on the entire primary key. Any attributes dependent on only part of the primary key are moved to separate tables.
Third normal form (3NF) takes normalization a step further by eliminating transitive dependencies. It ensures that all attributes are dependent only on the primary key and not on other non-key attributes. Attributes that depend on other non-key attributes are moved to separate tables, reducing redundancy and improving data integrity. Boyce-Codd Normal Form (BCNF) extends the principles of 3NF by requiring that every determinant is a candidate key, further minimizing redundancy and ensuring data consistency.
Fourth and fifth normal forms (4NF and 5NF) address more complex dependencies such as multi-valued and join dependencies. They ensure that tables have no independent multi-valued facts and that every join dependency is implied by the candidate keys. These higher normal forms are aimed at creating more refined database designs that are resilient to anomalies and ensure optimal storage and query performance.
While normalization techniques offer a systematic approach to database design, there are situations where intentional redundancy may be introduced through denormalization. Denormalization is often employed in data warehousing or scenarios where read performance is prioritized over write performance, as it can reduce the number of joins required to retrieve data. However, denormalization should be approached judiciously to avoid compromising data integrity. Overall, the choice of normalization technique depends on the specific requirements and constraints of the database application, with the goal of achieving a well-structured and efficient database design.
PRACTICAL EXAMPLES
Let's consider a practical example of database normalization using a simplified scenario of a library management system. We'll start with an initial unnormalized table and then progressively normalize it to higher normal forms.
Initial Unnormalized Table (Not in 1NF):
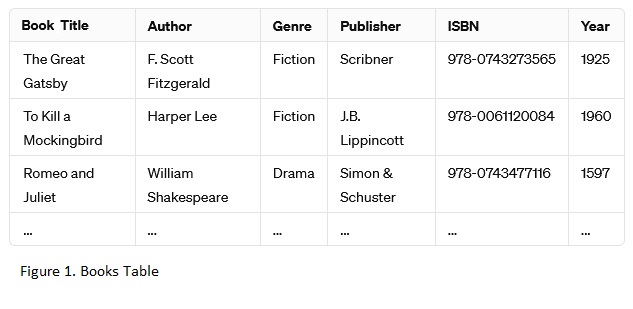
First Normal Form (1NF):
We need to ensure that each attribute contains atomic values and there are no repeating groups. To achieve this, we'll separate multi-valued attributes into distinct rows, and each row will have a unique identifier (primary key).
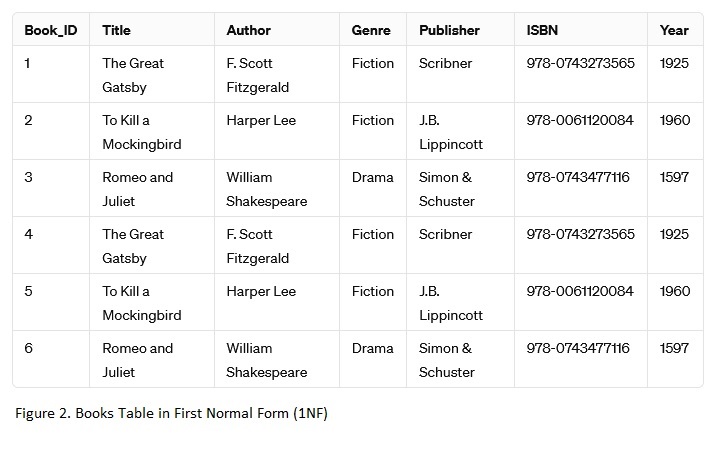
Second Normal Form (2NF):
Now, we ensure that all non-key attributes are fully functionally dependent on the entire primary key. We'll split the table into two tables: one for books and another for publishers.
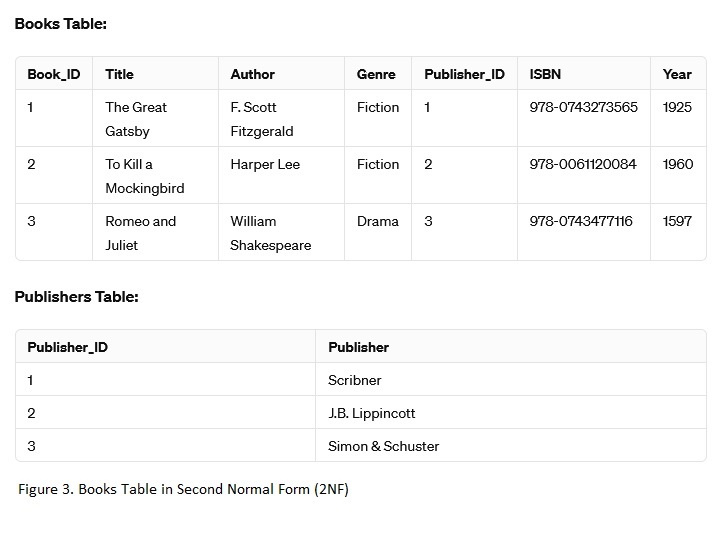
Third Normal Form (3NF):
Now, we ensure that all attributes are dependent only on the primary key and not on other non-key attributes. We'll introduce another table for genres.
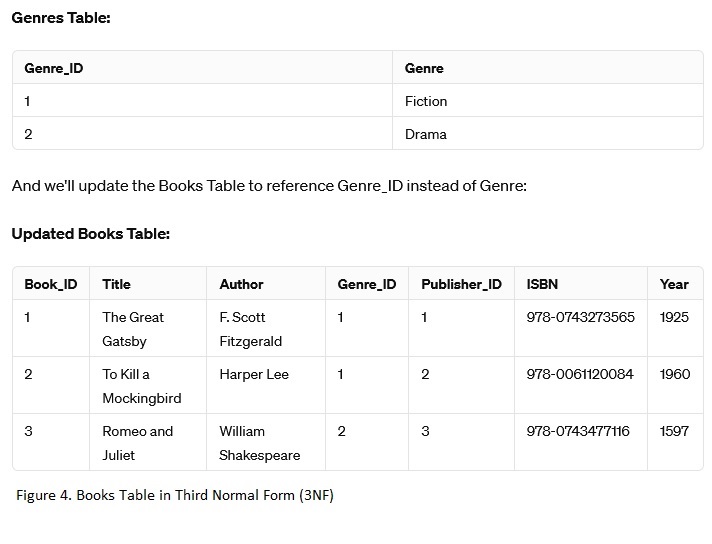
Further normalization can be done depending on the specific requirements and complexities of the database schema.
DENORMALIZATION
Denormalization is the process of intentionally introducing redundancy into a database schema to improve query performance or simplify data management, at the cost of data redundancy and potential integrity issues. It involves reorganizing a normalized database structure into a less normalized form.
Here are some scenarios where denormalization can be beneficial:
- Improving Query Performance: By reducing the number of joins needed to retrieve data, denormalization can speed up query execution. This is particularly useful in systems where read performance is critical, such as reporting or analytics applications.
- Reducing Complexity: Denormalization can simplify complex query logic by pre-joining tables or duplicating data, making queries easier to write and understand.
- Caching and Materialized Views: Denormalization can be used to create materialized views or cache frequently accessed data, further improving query performance by avoiding expensive joins.
- Offline Batch Processing: In some cases, denormalization is used to create denormalized copies of data for offline batch processing or reporting, without impacting the main operational database.
- Scaling Read-Heavy Workloads: In distributed or sharded database systems, denormalization can help distribute read-heavy workloads across multiple nodes by storing relevant data together, reducing the need for cross-node joins.
However, denormalization comes with trade-offs:
- Data Redundancy: Introducing redundancy can lead to data inconsistency if updates are not properly propagated across denormalized copies. It requires careful management and synchronization to ensure data integrity.
- Increased Storage Requirements: Denormalized schemas often require more storage space due to duplicated data, which can become significant for large datasets.
- Complexity of Updates: Updates, inserts, and deletes become more complex in denormalized schemas, as changes need to be propagated to multiple locations to maintain data consistency.
- Maintenance Overhead: Denormalized schemas require more effort to maintain, as changes to the data model or business rules may necessitate updates to multiple denormalized copies.
In summary, denormalization is a powerful optimization technique that can improve query performance and simplify data access, but it should be used judiciously and with careful consideration of the trade-offs involved. It's essential to weigh the benefits against the potential drawbacks and choose an appropriate denormalization strategy based on the specific requirements of the application.
NORMALIZATION IN DATABASE MANAGEMENT SYSTEMS
Normalization in database management systems (DBMS) is a systematic process aimed at structuring data efficiently to reduce redundancy, eliminate anomalies, and maintain data integrity. It starts with data modeling, where designers analyze system requirements and apply normalization rules to decompose tables into smaller, more granular forms. Progressing through normalization levels ensures increasingly refined schemas, while techniques like functional dependency analysis and key relationships aid in achieving optimal organization. Though normalization improves integrity, trade-offs like query performance must be considered. Ongoing maintenance and optimization are crucial for ensuring the database continues to meet evolving needs.
CHALLENGES AND CONSIDERATIONS
Database normalization is a fundamental aspect of database design, ensuring data integrity and efficiency. However, it introduces challenges such as potential performance overhead due to increased join operations and storage requirements, especially for large datasets. Moreover, the complexity of queries in normalized schemas and the risks associated with denormalization for performance optimization require careful consideration. Additionally, maintaining highly normalized schemas can be challenging, necessitating frequent schema changes and meticulous documentation to ensure manageability and integrity. Despite these challenges, normalization remains a crucial process for creating robust and scalable database systems.
To mitigate these challenges, designers must strike a balance between normalization principles and performance considerations, optimizing schema design for both efficiency and maintainability. This involves careful planning and analysis to minimize normalization overhead and storage costs while maximizing query performance. Additionally, adopting best practices for concurrency management and ensuring data consistency across transactions are essential for maintaining database integrity. By addressing these challenges thoughtfully and leveraging normalization techniques effectively, designers can create database schemas that meet the needs of their applications while ensuring data reliability and efficiency.
BEST PRACTICES AND RECOMMENDATIONS
Database normalization is essential for maintaining data integrity and optimizing database performance. Here are some best practices and recommendations to follow when normalizing a database:
- Understand Your Data: Thoroughly understand the data requirements and relationships before normalization.
- Follow Normalization Rules: Adhere to normalization rules, progressing from 1NF to 3NF as needed.
- Identify Functional Dependencies: Determine how attributes depend on each other to guide table decomposition.
- Choose Appropriate Keys: Select stable and unique primary keys for each table.
- Normalize to 3NF: Aim for at least Third Normal Form to minimize redundancy and dependency.
- Denormalize with Caution: Evaluate the trade-offs before denormalizing to improve performance.
- Optimize Indexing: Properly index normalized tables for efficient data retrieval.
- Regularly Review and Refactor: Refactor the schema as needed to accommodate changing requirements.
- Document the Schema: Document table structures, relationships, and constraints for clarity and maintenance.
- Test Performance: Perform performance testing to ensure the schema meets application requirements.
These practices will help ensure a well-structured and efficient database schema that supports your application effectively.
FUTURE DIRECTIONS AND CONCLUSION
Future directions in database normalization may involve exploring advancements in normalization techniques to address emerging challenges and evolving data management needs. This could include:
- Normalization for Big Data: Developing normalization techniques tailored to big data environments, where scalability, distributed processing, and real-time analytics are paramount. This might involve adapting traditional normalization principles to accommodate the unique characteristics of big data systems.
- Normalization for NoSQL Databases: Extending normalization principles to NoSQL databases, which often operate under different paradigms than traditional relational databases. This may involve defining normalization guidelines specific to document-oriented, graph, or key-value store databases.
- Normalization in Cloud Environments: Exploring normalization strategies optimized for cloud-native databases and serverless architectures. This could involve considering factors such as elasticity, multi-tenancy, and data partitioning in the context of normalization.
- Normalization for AI and Machine Learning: Integrating normalization techniques with AI and machine learning workflows to enhance data preprocessing and feature engineering processes. This may involve automated or semi-automated normalization methods tailored to data science pipelines.
- Normalization for Privacy and Security: Developing normalization approaches that prioritize privacy and security, particularly in light of increasing regulations such as GDPR and CCPA. This might include techniques for anonymizing or pseudonymizing data while preserving normalization principles.
In conclusion, database normalization remains a foundational concept in data management, providing a systematic approach to organizing and structuring data for efficiency and integrity. While traditional normalization principles continue to be relevant, future directions may involve adapting these principles to address evolving challenges in big data, NoSQL databases, cloud environments, AI, and privacy. By embracing these future directions, database normalization will continue to play a crucial role in ensuring robust and scalable data management solutions for diverse applications and industries.